Abstract
Images depicting complex, dynamic scenes are challenging to parse automatically, requiring both high-level comprehension of the overall situation and fine-grained identification of participating entities and their interactions. Current approaches use distinct methods tailored to sub-tasks such as Situation Recognition and detection of Human-Human and Human-Object Interactions. However, recent advances in image understanding have often leveraged web-scale vision-language (V&L) representations to obviate task-specific engineering. In this work, we propose a framework for dynamic scene understanding tasks by leveraging knowledge from modern, frozen V&L representations. By framing these tasks in a generic manner - as predicting and parsing structured text, or by directly concatenating representations to the input of existing models - we achieve state-of-the-art results while using a minimal number of trainable parameters relative to existing approaches. Moreover, our analysis of dynamic knowledge of these representations shows that recent, more powerful representations effectively encode dynamic scene semantics, making this approach newly possible.
How Does it Work?
-
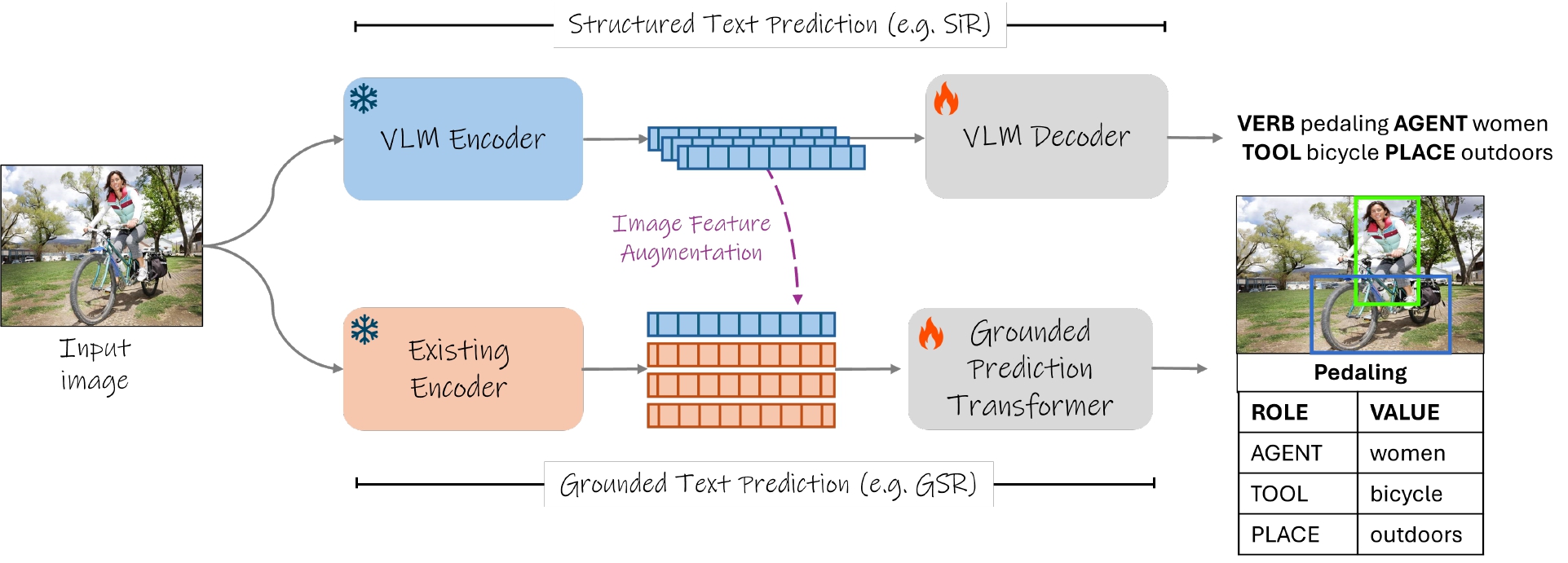
We propose a framework for using frozen multimodally pretrained vision representations to perform dynamic scene understanding tasks. This consists of two complementary methods for overall scene understanding and grounded prediction respectively. We illustrate our framework for performing high-level (top) and grounded (bottom) tasks, exemplified by the tasks of SiR and GSR in the figure. For overall scene understanding tasks we add trainable weights to the VLM text decoder and fine-tune these using a standard token-wise language modeling objective to predict the desired labels as formatted text. For grounded prediction tasks we concatenate the V&L embeddings to the existing vision backbone embeddings.
What Can it Do?
In this work, we bridge the gap in dynamic scene understanding by leveraging pretrained vision-language (V&L) representations as a strong semantic prior for complex scenes in images. By utilizing frozen vision representations, our framework achieves state-of-the-art performance across several dynamic scene understanding tasks—SiR, HHI, HOI, and GSR—with minimal task-specific engineering. Below we elaborate on each of these tasks, and provide visualizations of our results, comparing to prior work addressing these tasks.
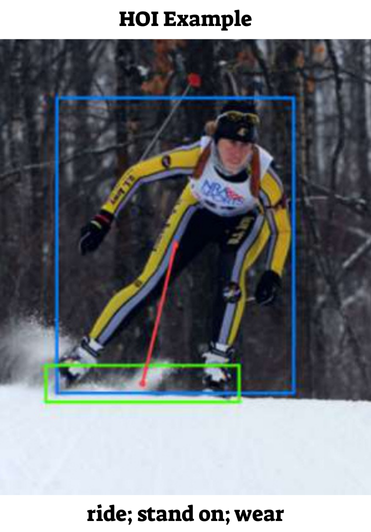
Human-Object Interaction (HOI)
The task of detecting human-object interactions involves localizing and classifying pairs of humans and objects interacting within an image. Interactions are typically represented as a triplet consisting of the object type, the specific interaction (action), and the corresponding bounding boxes for both the human and the associated object. For Interactive Visualization press the link below.
HOI - Interactive Visualization

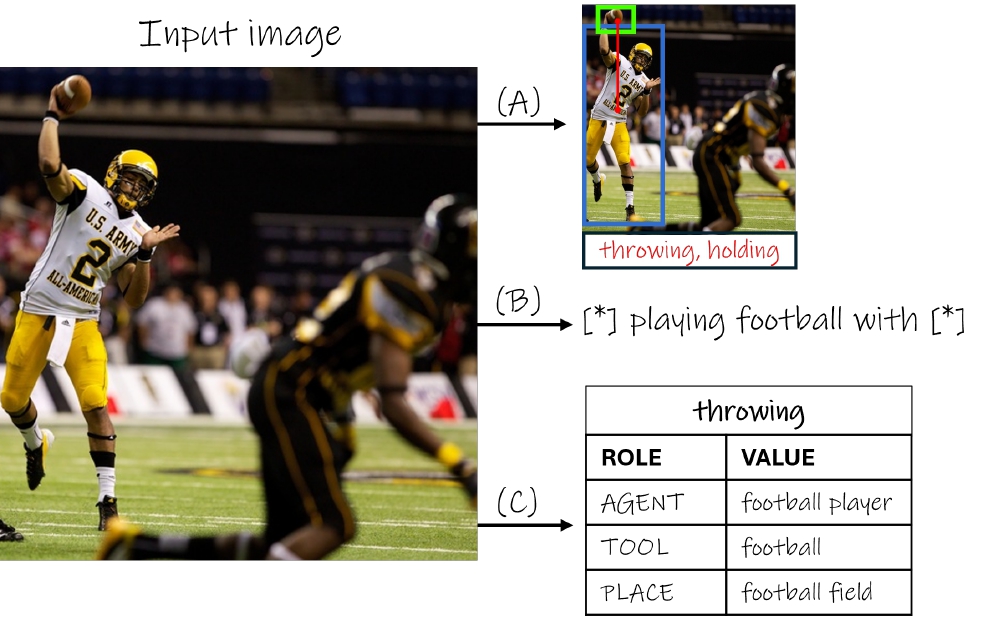
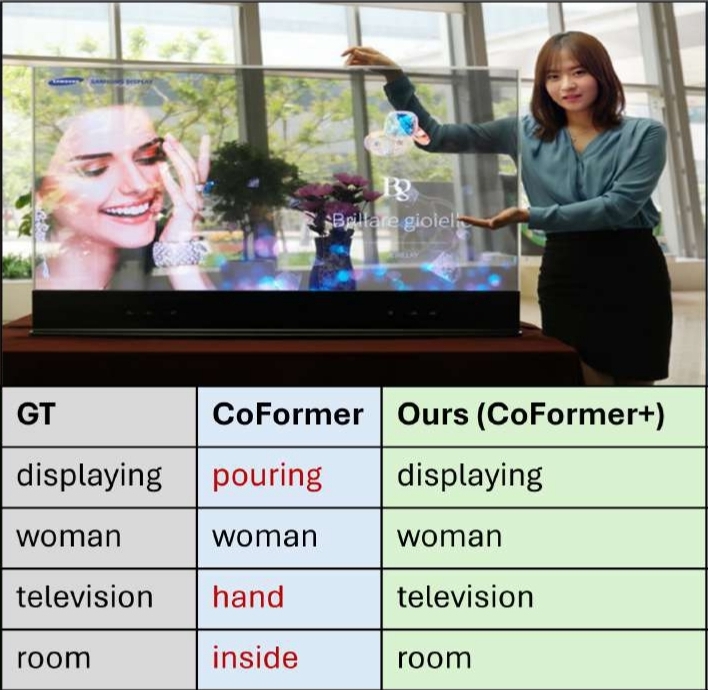
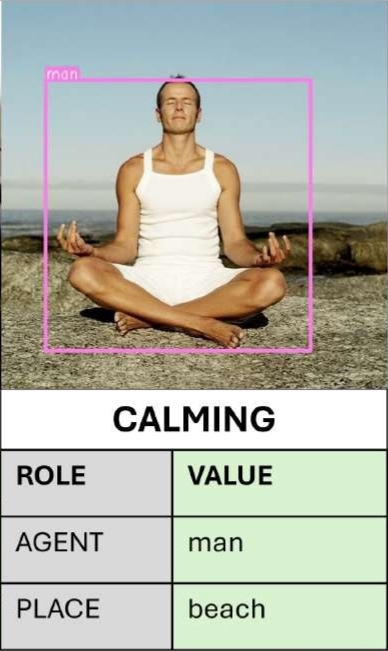
Situation Recognition (SiR)
The goal of SiR is to generate a structured summary of an image that captures the primary activity and the entities involved in specific roles, forming a semantic frame structure as defined in the field of linguistic semantics. In this formulation, the central activity being depicted corresponds to the chosen verb, whose arguments are nouns labelled by their task in this action. For Interactive Visualization press the link below.
SiR - Interactive Visualization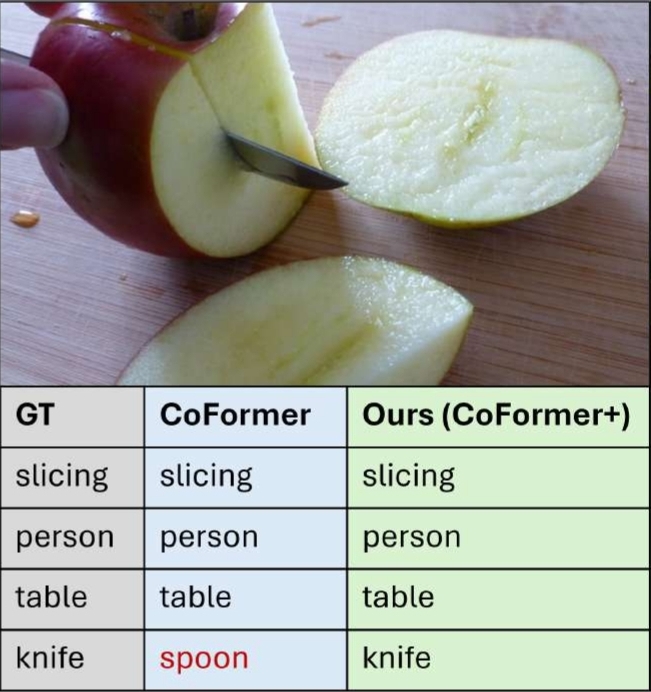

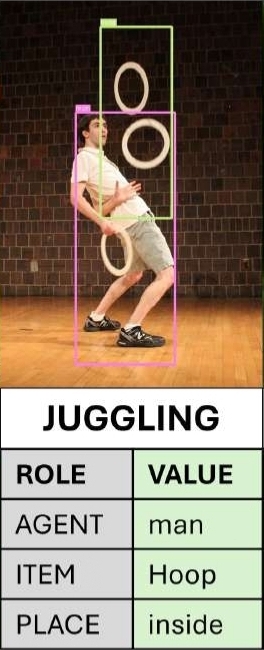
Grounded Situation Recognition (GSR)
GSR extends the SiR task by additionally expecting a bounding box prediction for each nominal argument, i.e. requiring a predicted location for each participant in the action. For Interactive Visualization press the link below.
GSR - Interactive Visualization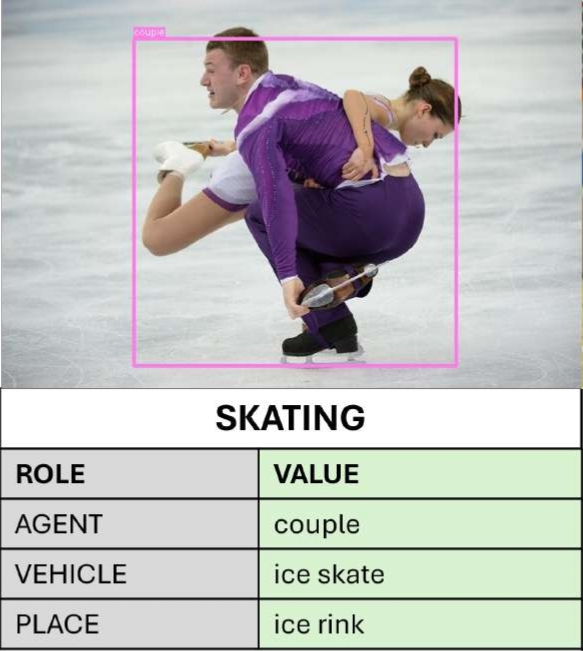


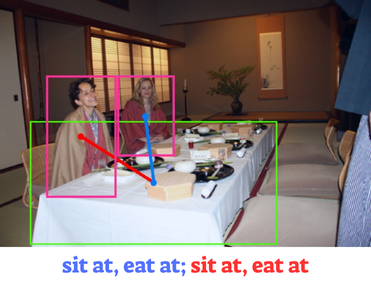
Human-Human Interaction (HHI)
The task of understanding interactions between humans bears similarity to HOI detection, but has attracted separate attention and approaches due to the complex nature of HHI as de pending on social context, their often non-local nature, and connection to human body pose. For Interactive Visualization press the link below.
HHI - Interactive Visualization



Additional Examples of Dynamic Scene Understanding
from Vision-Language Representations