Vox-E
Text-guided Voxel Editing of 3D Objects
Given multiview images of an object, our technique generates volumetric edits from target text prompts, allowing for significant geometric and appearance changes, while faithfully preserving the input object. The objects can be edited either globally or locally (local edits are emphasized in green).
Abstract
Large scale text-guided diffusion models have garnered significant attention due to their ability to synthesize diverse images that convey complex visual concepts. This generative power has more recently been leveraged to perform text-to-3D synthesis. In this work, we present a technique that harnesses the power of latent diffusion models for editing existing 3D objects. Our method takes oriented 2D images of a 3D object as input and learns a grid-based volumetric representation of it. To guide the volumetric representation to conform to a target text prompt, we follow unconditional text-to-3D methods and optimize a Score Distillation Sampling (SDS) loss. However, we observe that combining this diffusion-guided loss with an image-based regularization loss that encourages the representation not to deviate too strongly from the input object is challenging, as it requires achieving two conflicting goals while viewing only structure-and-appearance coupled 2D projections. Thus, we introduce a novel volumetric regularization loss that operates directly in 3D space, utilizing the explicit nature of our 3D representation to enforce correlation between the global structure of the original and edited object. Furthermore, we present a technique that optimizes cross-attention volumetric grids to refine the spatial extent of the edits. Extensive experiments and comparisons demonstrate the effectiveness of our approach in creating a myriad of edits which cannot be achieved by prior works.
How does it work?
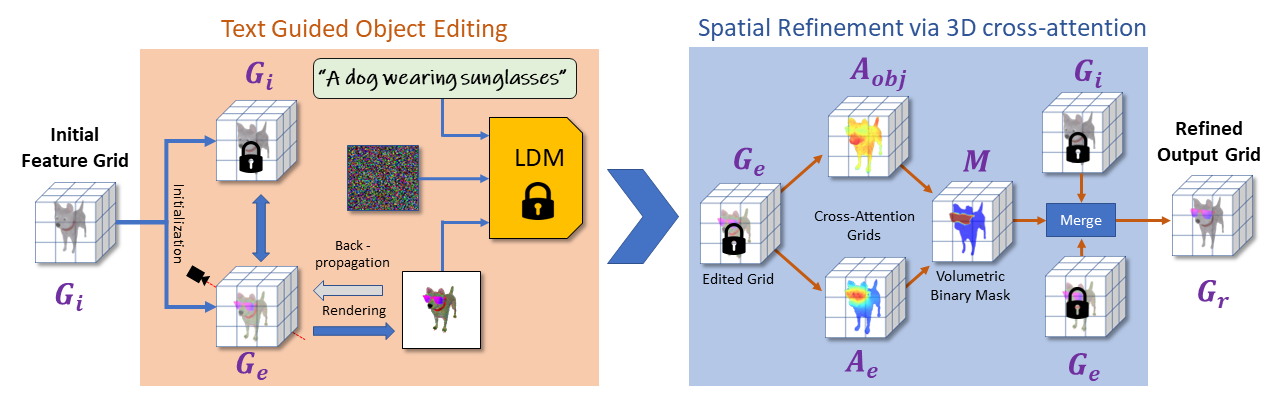
Given a set of posed multi-view images of an object (for example a dog in the example above) we first model the scene as a voxel grid where each voxel contains learned features (denoted as the "Initial Feature Grid" above). We then perform text-guided object editing by carefully applying a score distillation loss on an edited voxel grid. Our key idea is to regularize this process in 3D space by encouraging similarity between the structure of the edited grid and the initial grid. To further refine the spatial extent of the edits, we introduce an (optional) refinement stage that utilizes 2D cross-attention maps which roughly capture regions associated with the target edit and lift them to volumetric grids. We then use these 3D cross-attention grids as a signal for a binary volumetric segmentation algorithm that splits the reconstructed volume into edited and non-edited regions, allowing for merging the features of the volumetric grids to better preserve regions that should not be affected by the textual edit.
BibTeX
@misc{sella2023voxe,
title={Vox-E: Text-guided Voxel Editing of 3D Objects},
author={Etai Sella and Gal Fiebelman and Peter Hedman and Hadar Averbuch-Elor},
year={2023},
eprint={2303.12048},
archivePrefix={arXiv},
primaryClass={cs.CV}
}