Emergent Visual-Semantic Hierarchies
in Image-Text Representations
ECCV 2024 (Oral Presentation)
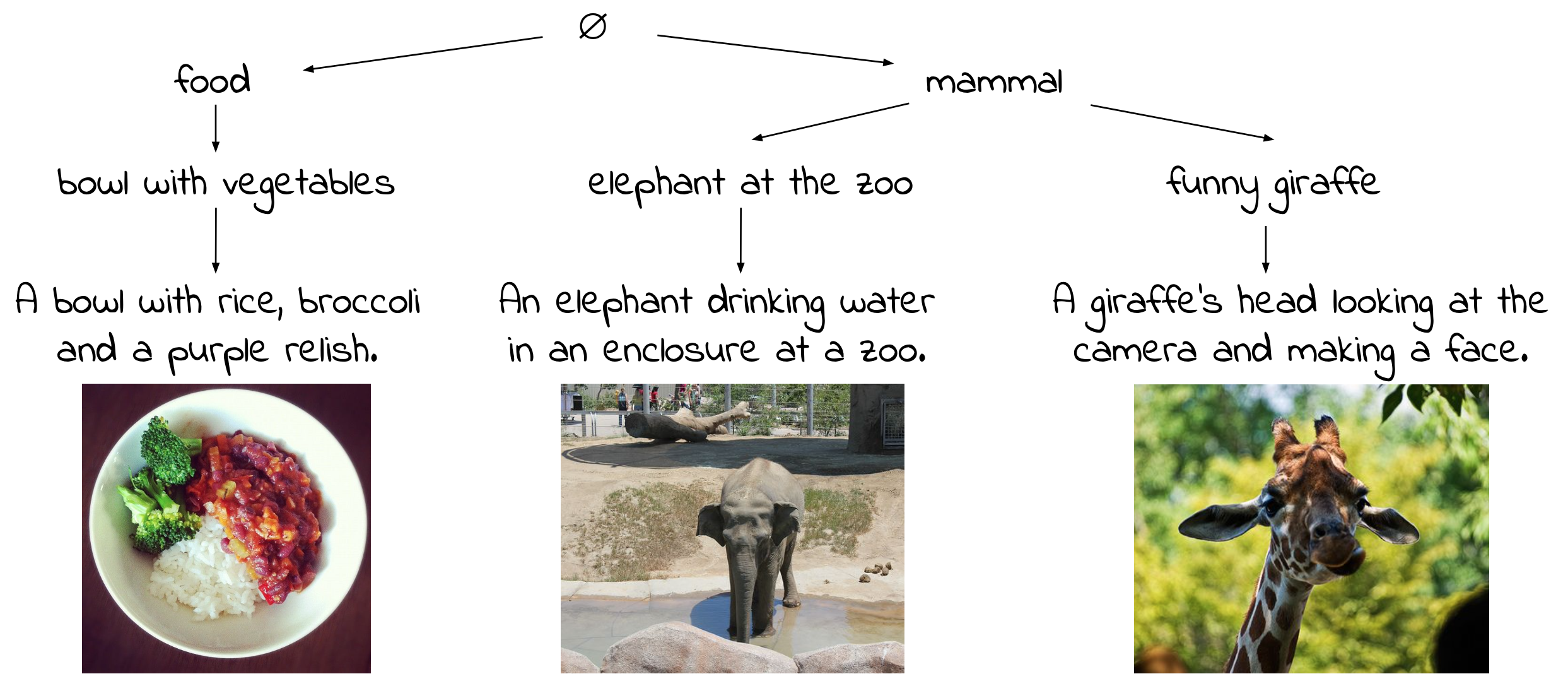
TL;DR: Foundation VLMs like CLIP model visual-semantic hierarchies like the one shown above.
Abstract
While recent vision-and-language models (VLMs) like CLIP are a powerful tool for analyzing text and images in a shared semantic space, they do not explicitly model the hierarchical nature of the set of texts which may describe an image. Conversely, existing multimodal hierarchical representation learning methods require costly training from scratch, failing to leverage the knowledge encoded by state-of-the-art multimodal foundation models. In this work, we study the knowledge of existing foundation models, finding that they exhibit emergent understanding of visual-semantic hierarchies despite not being directly trained for this purpose. We propose the Radial Embedding (RE) framework for probing and optimizing hierarchical understanding, and contribute the HierarCaps dataset, a benchmark facilitating the study of hierarchical knowledge in image–text representations, constructed automatically via large language models. Our results show that foundation VLMs exhibit zero-shot hierarchical understanding, surpassing the performance of prior models explicitly designed for this purpose. Furthermore, we show that foundation models may be better aligned to hierarchical reasoning via a text-only fine-tuning phase, while retaining pretraining knowledge.
Probing and Optimizing with the RE Framework
Our Radial Embedding (RE) framework defines geometric relations between embeddings in VLMs such as CLIP which we find effectively encode hierarchical knowledge. The RE framework is designed to flexibly adapt to the emergent geometry of such VLMs, contrasting with prior approaches that train hierarchical models from scratch with stricter geometric assumptions. In addition to zero-shot probing, RE can be used to align VLMs with a light-weight fine-tuning stage to enhance hierarchical understanding, using the RE loss illustrated below:
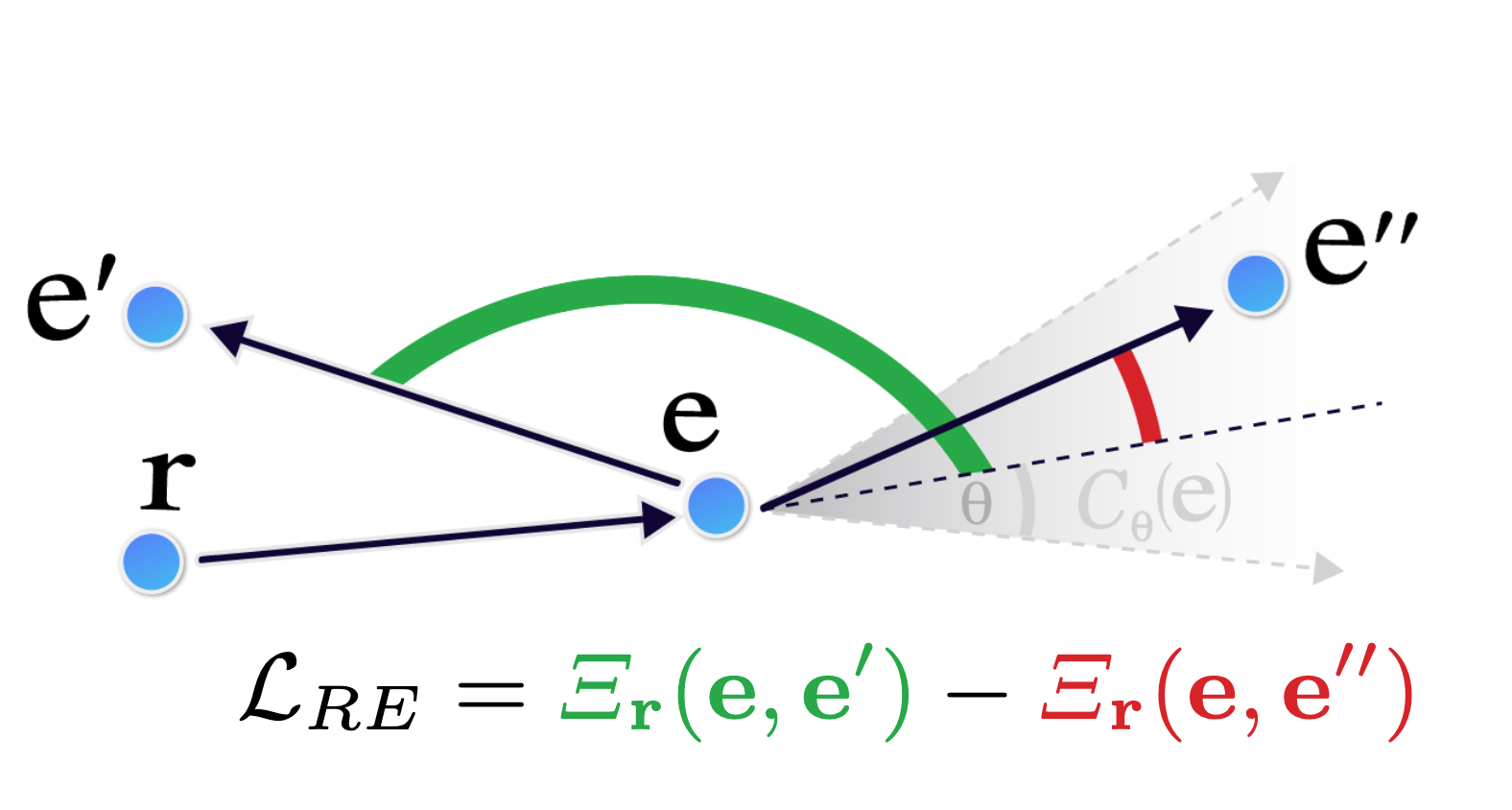
This is a contrastive loss based on the learnable root embedding r and the triplet (e, e', e'') of caption text embeddings selected to include logical entailment and contradiction relations. See our paper for further technical details.
The HierarCaps Dataset
We propose the HierarCaps dataset consisting of images with paired ground-truth caption hierarchies, as shown below:

As existing image captioning datasets only have a single caption (or unrelated reference captions) for each image, we leverage existing paired image-caption datasets along with an LLM and NLI-based pipeline to generate logical caption hierarchies. Our train set consists of over 70K paired images and captions, while we manually curate 1K items as a clean test set. We also contribute quantitative metrics for hierarchical understanding on HierarCaps.
Code, Trained Models, and Results
We release our code and trained models, anticipating further research on visual-semantic hierarchical understanding. We also provide a interactive visualization of model results on the HierarCaps test set, as well as a random subset of the HierarCaps train set.
Acknowledgements
We thank Yotam Elor, Roi Livni, Guy Tevet, Chen Dudai, and Rinon Gal for providing helpful feedback. This work was partially supported by ISF (grant number 2510/23).
Citation
@InProceedings{alper2024hierarcaps,
author = {Morris Alper and Hadar Averbuch-Elor},
title = {Emergent Visual-Semantic Hierarchies in Image-Text Representations},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2024}
}